카프카의 주요 개념
카프카의 탄생 배경
-
카프카 등장 이전에는 단방향 통신 방식을 주로 사용하였으며, 이는 application 간 1:1 직접적으로 연결되는 방식이다.
-
아키텍쳐가 거대해짐에 따라 소스 애플리케이션과 타겟 애플리케이션간 연결되는 라인이 늘어나기 시작함으로 장애 관리가 어려워지고 복잡성이 증가한다.
즉 소스 애플리케이션에서 장애가 발생하면 이는 타겟 애플리케이션에 그대로 영향을 미친다.
- 카프카를 중앙에 배치함으로서 소스 애플리케이션과 타겟 애플리케이션간 의존도를 최소화할 수 있다. 즉 어느 한쪽에서 이슈가 발생하더라도 장애가 전파되지 않는 구조이다.

카프카의 장점
높은 처리량
대량의 데이터를 송수신할때, 네트워크 통신 횟수를 최소한으로 줄이기 위해서 묶어서 송신한다. 즉 배치 처리가 가능하다. 파티션 단위로 병렬처리가 가능하다. 파티션 별로 데이터를 분배하고 , 파티션 개수만큼 Consumer 개수를 늘려서 동일 시간당 데이터 처리를 늘리는 방식이다.
확장성
트래픽에 따라 브로커의 개수를 조정하는 식으로 Scaling이 가능하다. 트래픽이 적을때는 최소한의 개수로 운영하다가 트래픽이 많아지면 브로커의 개수를 늘려서 대응할 수 있다.
영속성
카프카에서는 다른 메시지 큐와 다르게 파일 시스템에 데이터를 저장한다. 따라서 브로커가 비정상적으로 종료되더라도 소실되지 않는다.
매번 디스크에 읽기 요청이 나가는 것은 아니며,운영체제 수준에서 최적화 기법을 사용한다. page cache 를 통해 영구 저장장치에 대한 접근 비용을 줄일 수 있다. 한번 읽은 page는 memory에 cache하고 있다가 읽기 요청이 들어오면 Disk까지 I/O요청이 나가지 않고, memory에서 바로 읽기가 가능하다.
당연히 Consumer가 데이터를 들고 가더라도 데이터는 삭제되지 않는다. 데이터 삭제는 오직 브로커에서만 가능하다. 브로커에서는 다양한 데이터 삭제 정책이 존재한다. (용량 기반/시간 기반)
다음과 같이 데이터 삭제 정책을 브로커에 지정할 수 있다.
// 카프카 브로커의 server.properties 설정 파일
log.retention.bytes = ${임계치바이트수}
log.retention.ms = ${임계치시간}
고가용성
카프카는 1대로 운영할수도 있지만, 일반적으로 3대 이상의 broker를 구성해 cluster를 구축하여 사용한다. 그래야만 일부 서버에서 장얘가 발생하더라도 서비스 중단없이 데이터를 처리할 수 있다.
고가용성을 보장하고자 카프카는 수신받은 데이터를 복제하여서 여러 서버에 분산 저장한다. 즉 한 쪽에서 소실되더라도 나머지 서버에서 처리가 가능하다.
- 데이터 복제 방식
카프카에서는 파티션 단위로 데이터를 복제한다. 따라서 파티션을 생성할때에도 replication-factor 인자를 통해 몇개의 파티션에 데이터가 동일하게 복제될것인지 설정할 수 있다.
$ kafka-topics.sh
--create
--bootstrap-server localhost:9092
--replication-factor ${복제개수}
--partitions ${파티션개수}
--topic ${토픽명}
당연히 복제가능한 최대개수는 카프카 브로커 개수만큼이다.
- Leader Partition 과 Follower Partition
정리하면 토픽은 일련의 데이터 스트림이다. 그리고 이 토픽은 여러 개의 파티션으로 구성될 수 있다. 각 파티션은 브로커 서버에 위치하며, leader 와 follower로 구분된다.
leader는 application(consumer/producer)과 직접 통신하는 파티션이고, follower는 나머지 복제본을 들고 있는 파티션을 지칭한다.
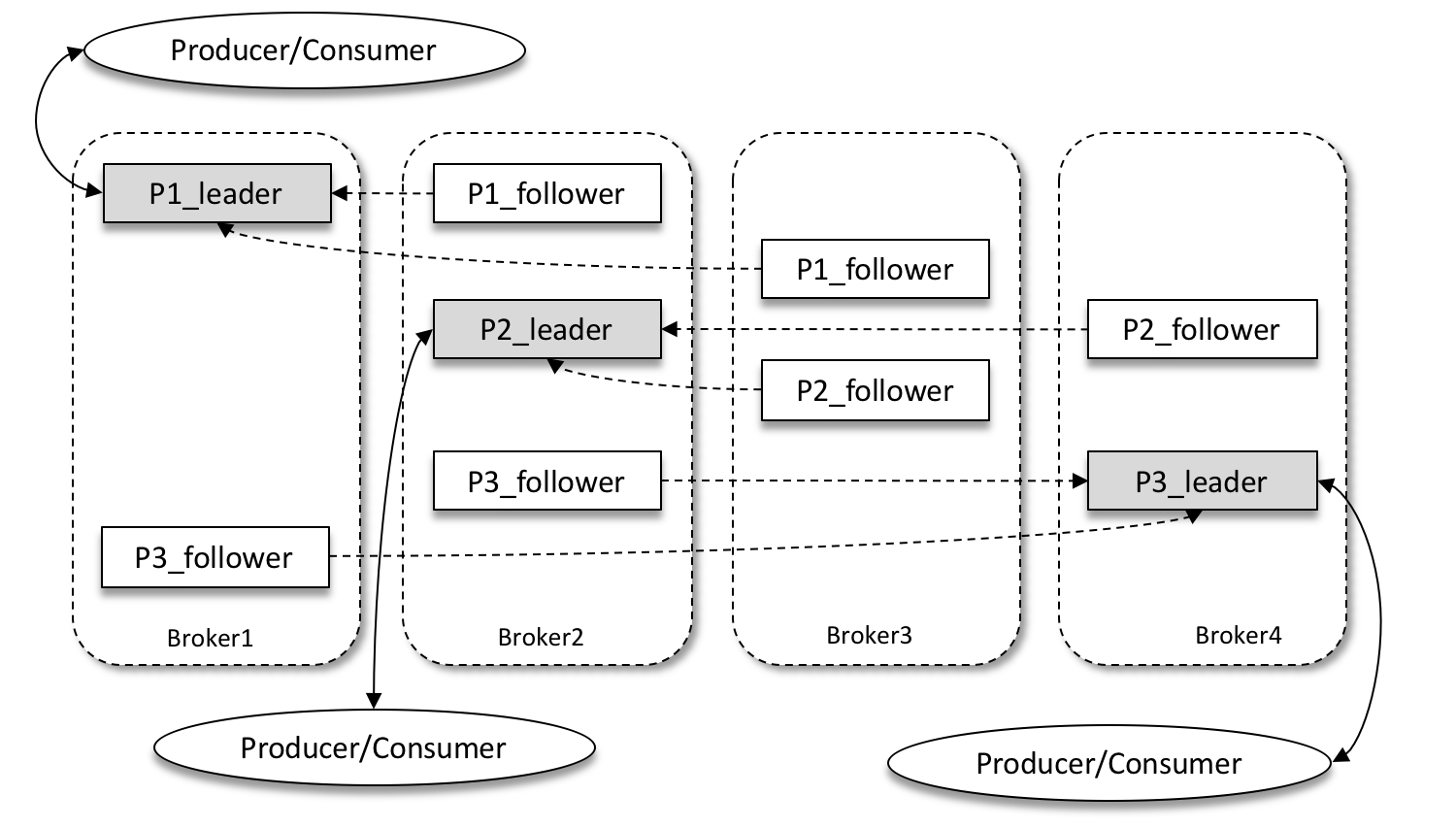
follower는 leader patition과 offset을 비교해서, 자신이 들고 있는 offset과 차이가 나는 경우에는 leader로부터 데이터를 복제해온다.
만약 leader가 장애가 발생하면 나머지 follower중에 하나의 서버가 leader가 된다.
그러면 어떻게 leader가 장애가 발생하였는지 탐지하고 follower중에 하나를 leader로 승격(?)시킬까? 카프카에서는 해당 역할을 담당하는 Controller Component가 존재한다.
- Controller
브로커중 한 대가 Controller의 역할을 수행한다.
일종의 health-check기능을 하는 셈이다.
다른 브로커들의 상태를 지속적으로 체크하고, 브로커 한대가 장애가 발생해서 cluster에서 빠지게 되면, 해당 브로커에 존재하는 leader 파티션을 다른 broker가 수행할 수 있도록 한다.
- Coordinator
또 다른 브로커 서버가 수행하는 역할 중 하나는 “Coordinator” 역할이다. Coordinator는 Consumer Group의 상태를 확인하고 Partition과 Consumer를 매칭시키는 역할을 한다. 여기서 Consumer Group이란 말 그대로 하나 이상으로 이루어진 Consumer 애플리케이션을 지칭한다. Consumer가 그룹에서 제외되는 경우, 기존에 연결된 파티션은 또 다른 Consumer로 매칭되야 한다.
예를 들어서, 4개의 파티션이 4개의 Consumer와 각각 1:1매핑된 상황에서 Consumer가 의도하거나 의도치 않은 상황으로 제외되었다면 매칭되지 않은 파티션이 하나 나올 것이다. 이때 Rebalancing 이라는 과정이 일어나 파티션을 Consumer로 할당해준다.
Reference
[1] https://www.tibco.com/ko/reference-center/what-is-apache-kafka